1.决策树
注:以下内容来自吴恩达老师的机器学习课程和周志华老师的《机器学习》
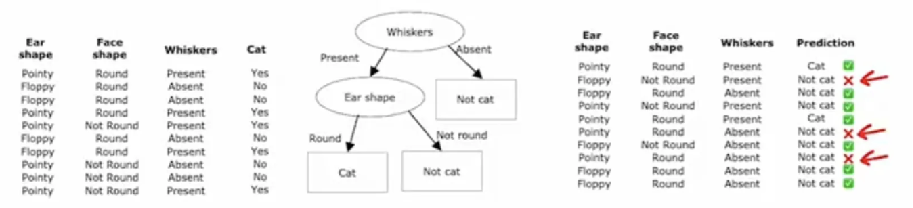
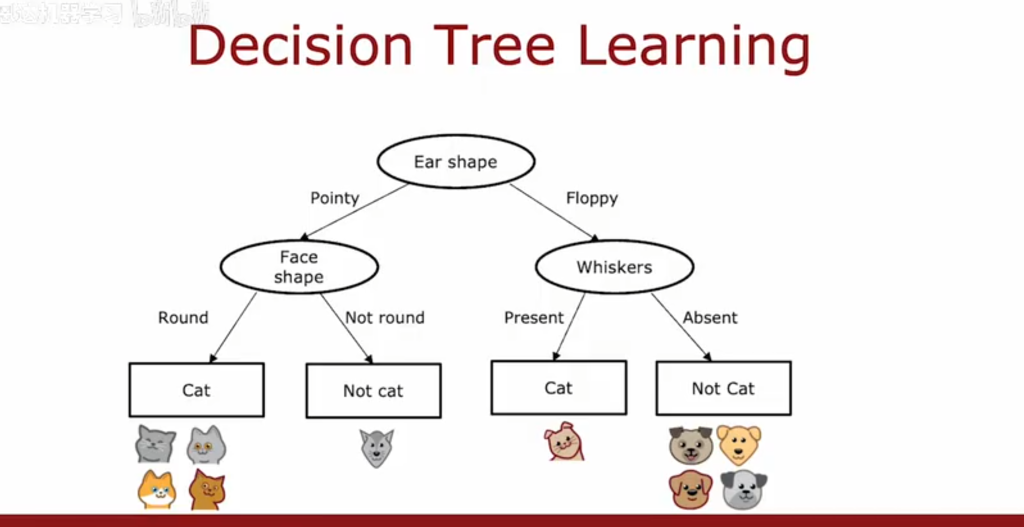
1.1决策树原理示例图
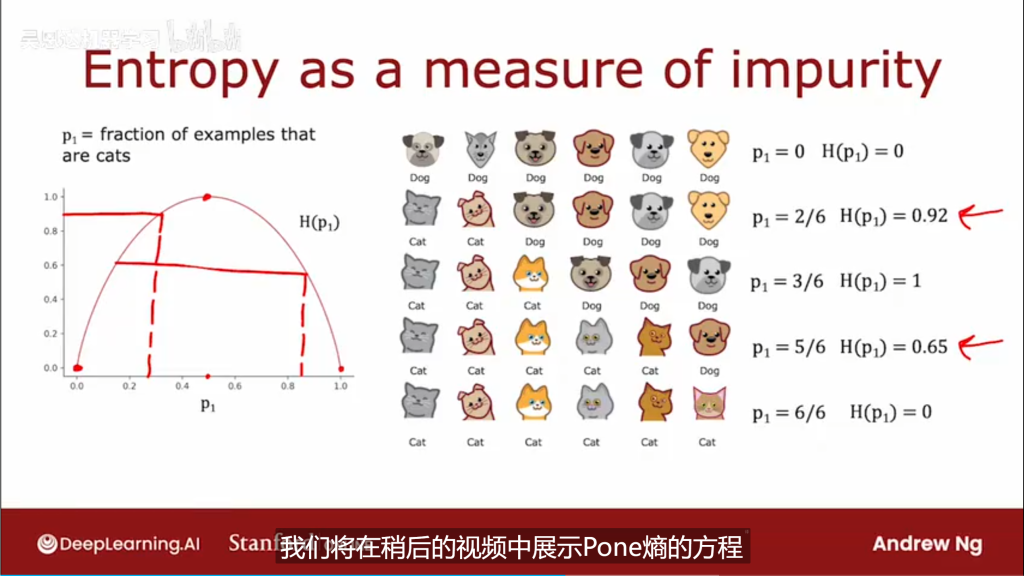
1.2纯度和信息增量
我们面临两个问题:1.如何选择分类特则; 2.何时停止分类
为解决以上两个问题,引入概念“纯度”和“信息增量”
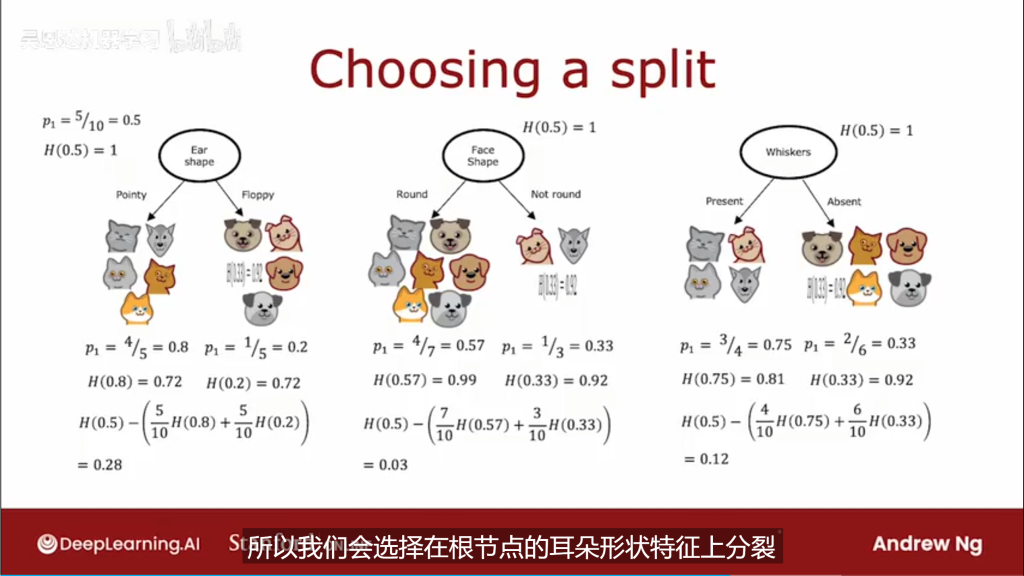
1.2.1如何选择分类特则?


信息增量计算示例
1.2.2何时停止分裂
当一个节点100%是一个类时
当拆分一个节点时,树将超出最大深度
当节点中的示例数低于阈值时
当纯度分数的提高低于阈值时
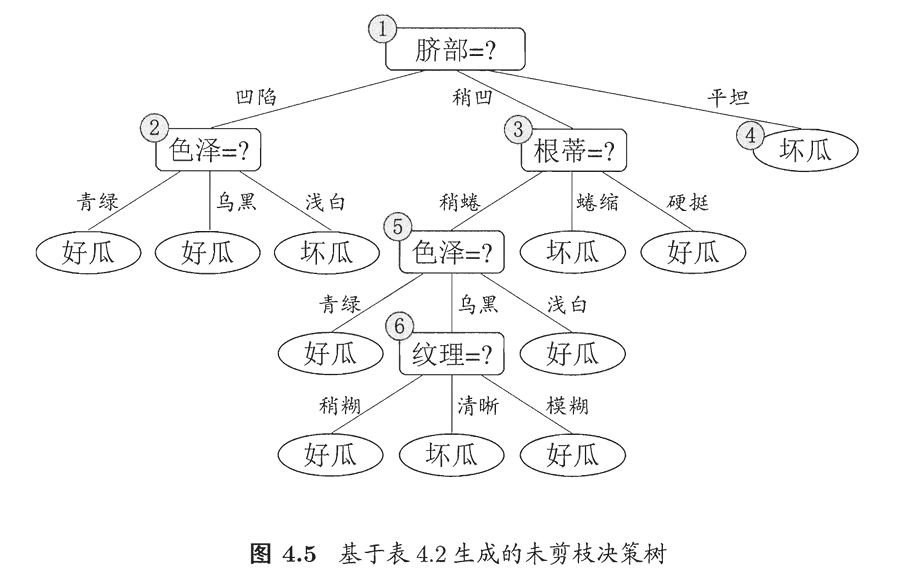
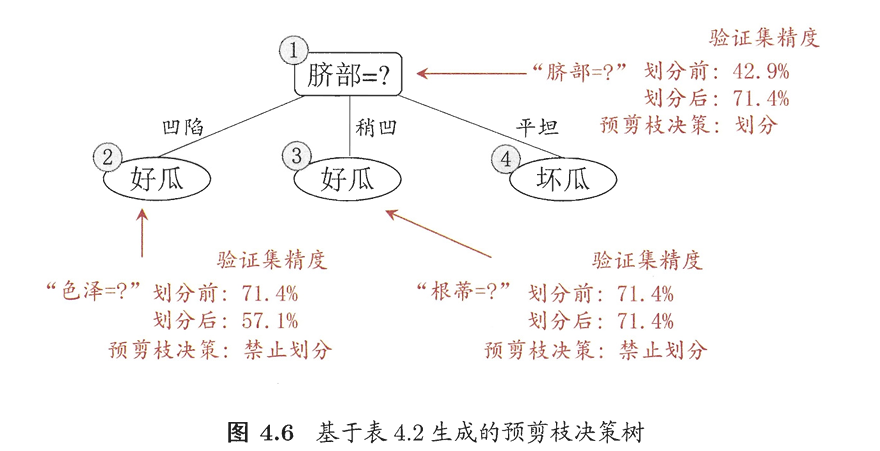
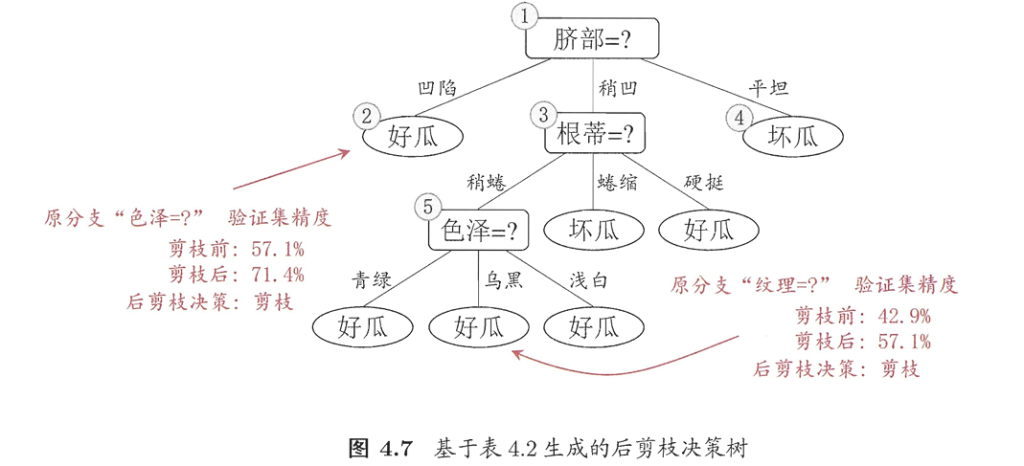
1.3剪枝处理
剪枝是决策树学习算法对付过拟合的手段
预剪枝:决策树生成过程中,对每个结点在划分前先进性估计,若当前节点的划分不能带来决策树范化能力的提升,则停止划分并将当前节点标记为叶节点。
后剪枝:先从训练集生成一颗完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能的提升,则将该子树替换为叶节点。
1.4连续值处理
将连续型变量a的n个不同取值按从小到大排序,
令ai为a中·任一个元素,则我们可以(ai+ai+1)/2作为划分点,可得到n-1个划分点
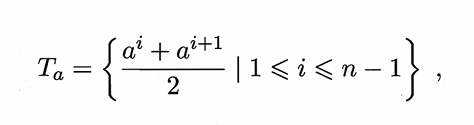
最后寻找使得信息增益最大的划分点
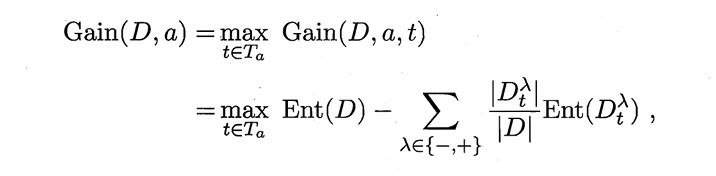
1.5缺失值处理
待解决的两个问题:
如何在属性值缺失的情况下进行划分属性选择?
答:根据没有缺失值的样本子集确定分类属性
给定划分属性,若样本在该属性上的值缺失,如何对样本进行划分?
答:若样本x在划分属性a上的取值未知,将x同时划入所有子节点,且样本权值在与属性值av对应的子结点中调整为该取值在未缺失样本中的比例。
举例



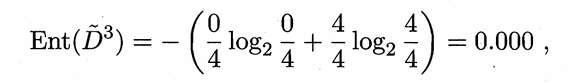



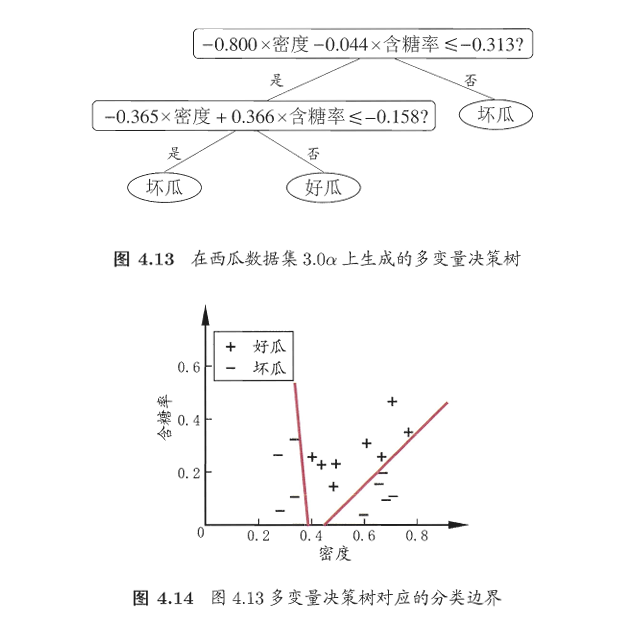
1.6多变量决策树
决策树所形成的分类边界有一个明显的特点:轴平行(axis-parallel),即它的分类边界由若干个与坐标轴平行的分段组成.
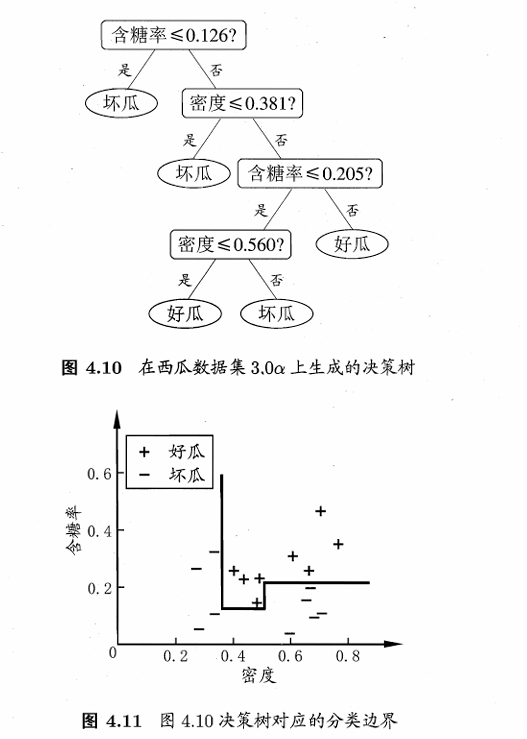
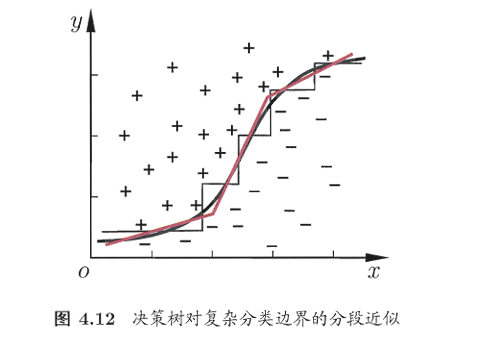
若能使用斜的划分边界,如图4.12中红色线段所示,则决策树模型将大为简化.“多变量决策树”(multivariate decision tree)就是能实现这样的“斜划分”甚至更复杂划分的决策树.以实现斜划分的多变量决策树为例,在此类决策树中,非叶结点不再是仅对某个属性,而是对属性的线性组合进行测试。
2.决策树衍生算法
2.1决策树的弊端
决策树的缺陷:样本细微改变可能导致决策树结构完全不同
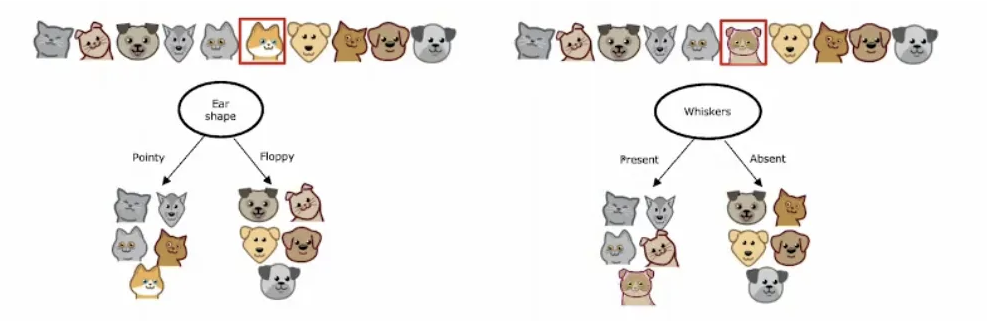
解决方案引入集成学习的思想
2.2集成学习简介
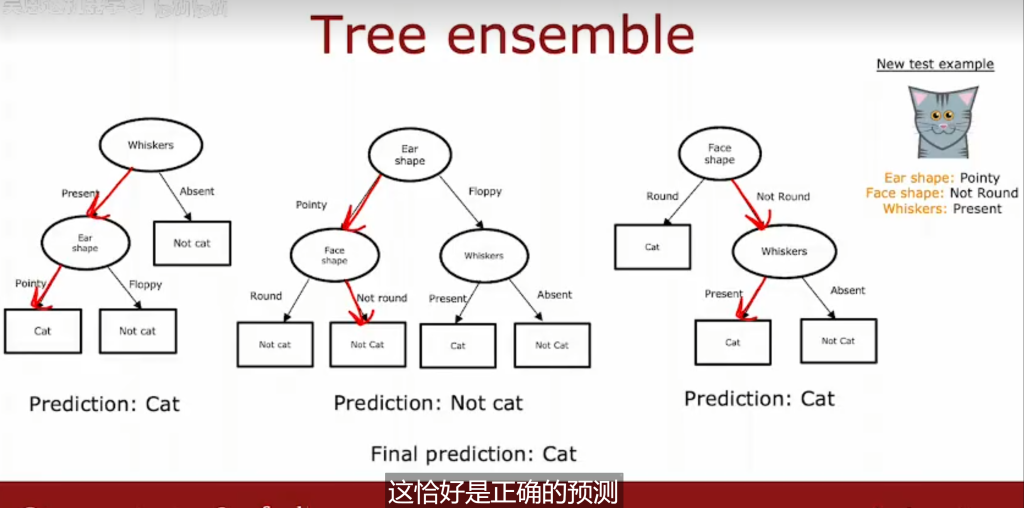
集成学习:通过构建并结合多个学习器来完成学习任务。
1.个体学习器间存在依赖关系,必须串行生成的序列化方法,代表Boosting,XGBDT
2.个体学习器间不存在依赖关系,可同时生成的并行化方法,代表Bagging,随机森林
2.3随机森林算法
2.3.1 算法原理简介
给定包含m个样本的数据集,经过m次又放回随机采样操作,我们得到含m个样本的采样集,初始训练集中约有 63.2%的样本出现在采样集中.照这样,我们可采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。
传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分.这里的参数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同:若令k=1,则是随机选择一个属性用于划分。

2.3.2参数调整
mtry 随机选择的特征变量个数
ntree 模型生成并结合的决策树数量
2.3.3变量重要性
对于二分类因变量,常用的变量重要性指标为:
- Mean Decrease Accuracy(平均准确率下降):表示移除某个变量后,模型预测准确率的下降幅度。这个指标同样越大,说明该变量对模型的重要性越大。
对于连续型因变量,常用的变量重要性指标有:
Mean Decrease Accuracy 是通过对预测准确率的下降来衡量变量的重要性,但在回归问题中,预测准确率的概念并不适用,因此这个指标通常不用于回归模型。
- %IncMSE(% Increase in Mean Squared Error):表示当某个变量被移除时,模型的均方误差(MSE)增加的百分比。这个指标越大,说明该变量对模型的重要性越高。
- IncNodePurity(Increase in Node Purity):表示在树的分裂过程中该变量对节点纯度(例如,Gini指数或方差)的贡献。值越高,说明该变量对模型的重要性越大。
2.4 极致梯度提升决策树XGBDT
2.4.1 xgbdt原理简介
算法基于boost思想,即先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值T,最终将这T个基学习器进行加权结合.