1. 基本思想 TOPSIS(Technique for Order Preference by Similarity to Ideal Solution) 是一种常用的多指标综合评价方法。 基本思路:选择出一个 正理想解(各指标最优值组成)和一个 负理想解(各指标最劣值组成),通过比较各评价对象与理想解的距离,得到综合贴近度作为排序依据。 熵权法…
所用R包:rms 核心思想 节点 (Knots):将连续变量 X 的取值范围划分为多个区间。常见的节点数量是 4 或 5 个,通常放置在分位数上(如 5th, 35th, 65th, 95th)。 基函数 (Basis Functions):为每个区间创建一个三次多项式,但有一个关键限制:要求在节点处函数、一阶和二阶导数都是连续…

广义估计方程 补充:广义估计方程与重复测量方差分析的区别(个人观点): 都可用于重复测量数据的组间及时间差异分析 重复测量方差分析 适用于:时间变量为因子 优势:时间可不等距 综合考虑任两个时间点或任两组间的差异 而GEE需要设定某一时间(组)为参照或设置为连续值(但此时需要等距) 缺点:缺少两两比较的方法 广义估计方程 优势:可设立相关结构、可通…
概率图模型(probabilistic graphical model)是一类用图来表达变量相关关系的概率模型.它以图为表示工具,最常见的是用一个结点表示一个或一组随机变量,结点之间的边表示变量间的概率相关关系,即“变量关系图”.根据边的性质不同,概率图模型可大致分为两类: 第一类是使用有向无环图表示变量间的依赖关系,称为有向图模型或贝叶斯网(Ba…
整合了两因素重复测量方差分析及均值误差折线图所用代码 所用r包: broom、data.table、Rmisc 汇总结果表 注:日常工作中常遇到需要整理重复测量方差分析表,该表需结合t检验、单因素方差分析及单组及两因素重复测量方差分析,若分步骤处理较为麻烦,因而我整理了一个自定义函数可快速生成该表格 自定义函数 library(tidyverse)…
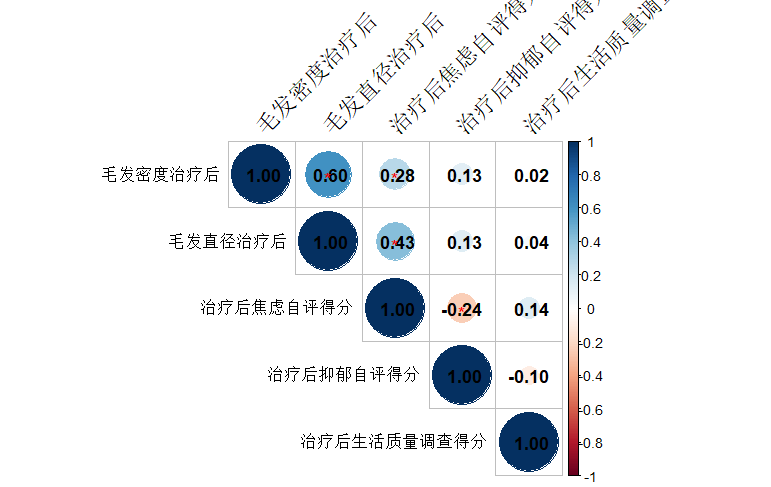
注:所用r包rcompanion、corrplot 相关性分析 library(rcompanion) cor_result <- rcorr(as.matrix(adam[,c(5,7,9,11,13)]), type = "spearman") cor_matrix <- cor_result$r #相关性矩阵 p_valu…
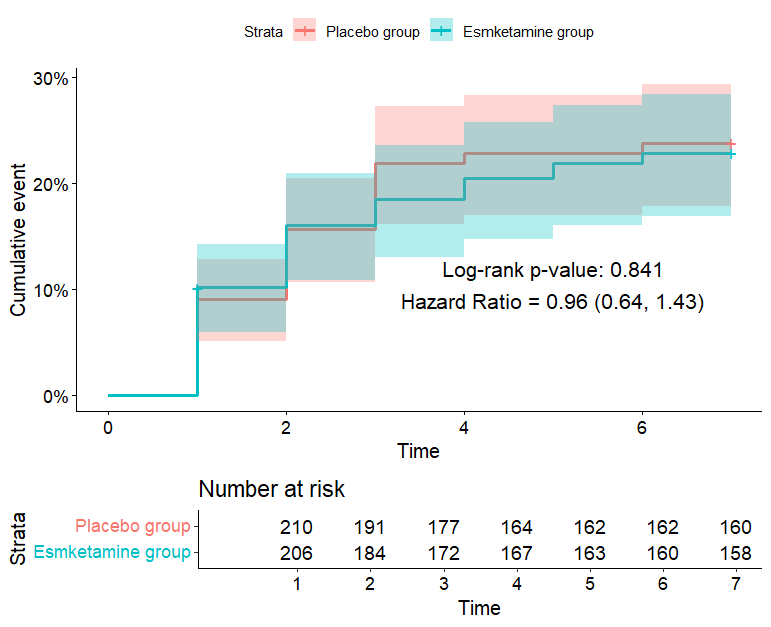
注:所用r包 survminer 准备工作 logrank示例数据下载 library(openxlsx) #读取数据 library(survival) #生存分析 library(survminer) #结果可视化 tt <- read.xlsx("logrank示例数据.xlsx") logrank检验和cox生存分析 log_rank…
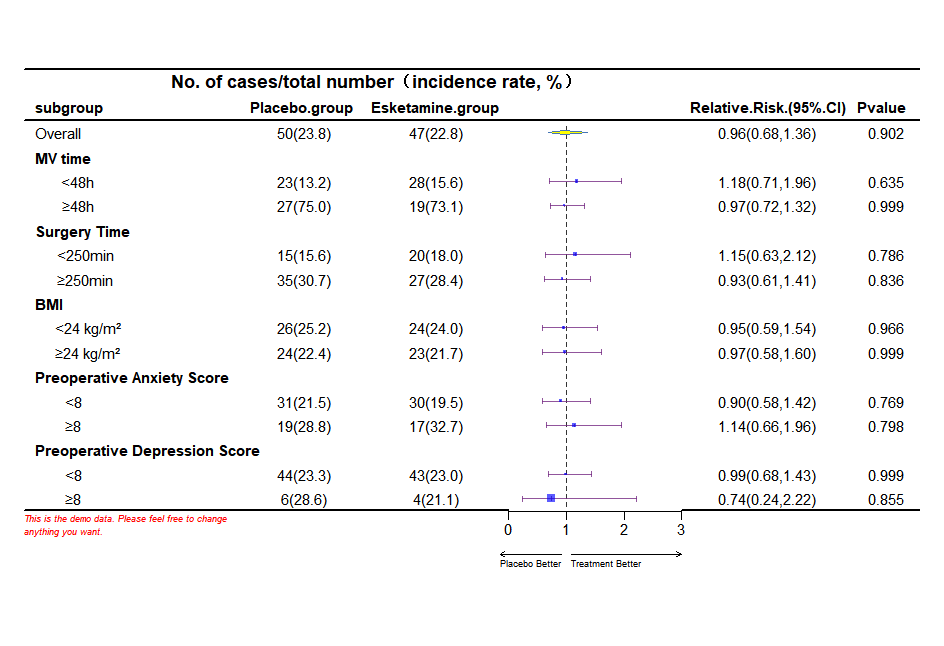
所用R包: forestplot , forestploter 示例数据 森林图示例数据下载 单列森林图(forestplot包) 官方文档:Introduction to forest plots #forestplot包森林图代码附注释 library(forestplot) data <- read.xlsx("森林图示例数据.xlsx…
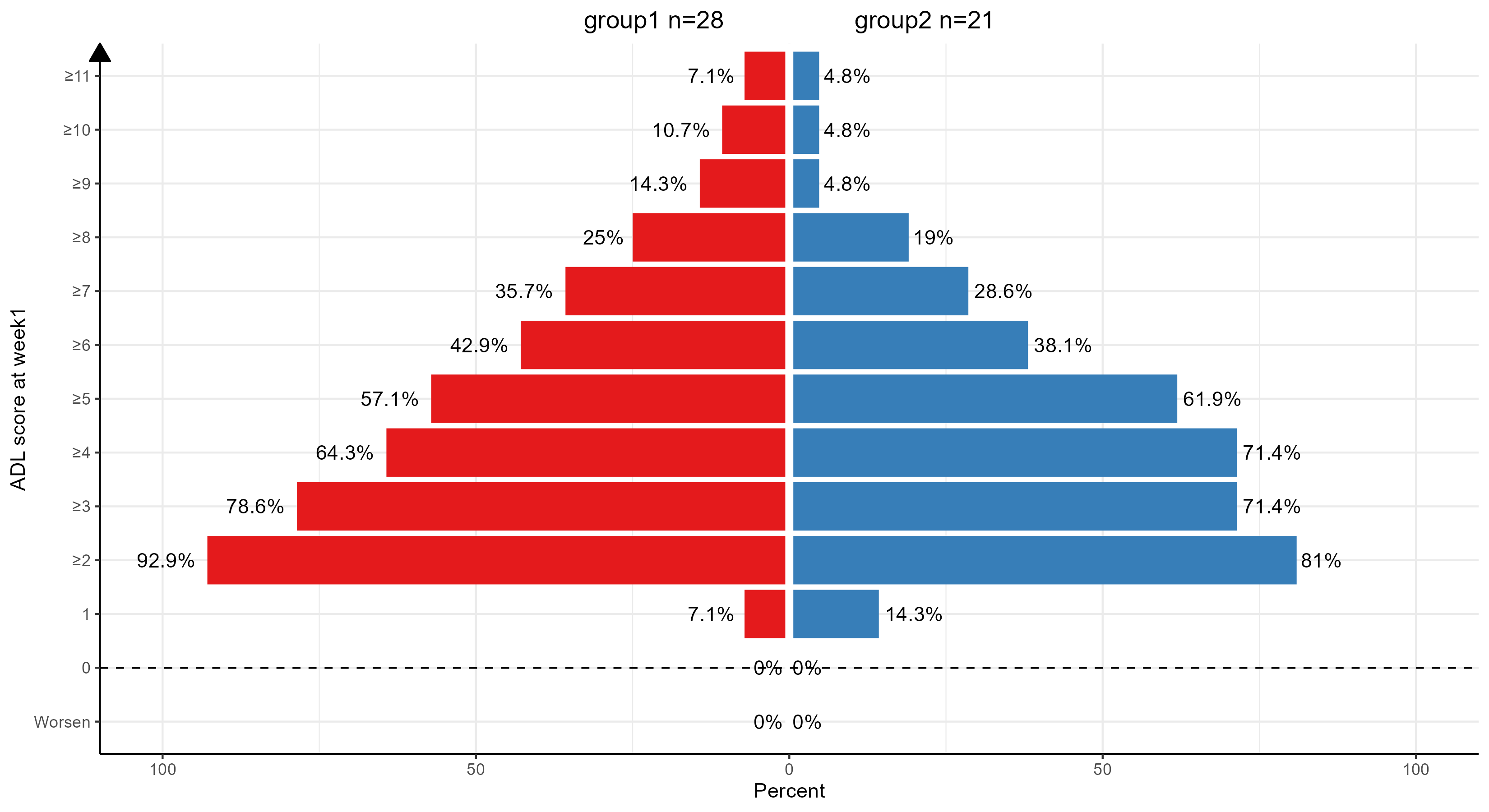
所用R包: ggplot2 1.数据准备 # 定义一个函数,用于生成每个变量的绘图所用数据 generate_test_data <- function(variable) { # 统计每列中大于 1、2、3。。。。的个数 count_values <- function(column) { c( sum(column < 0, …
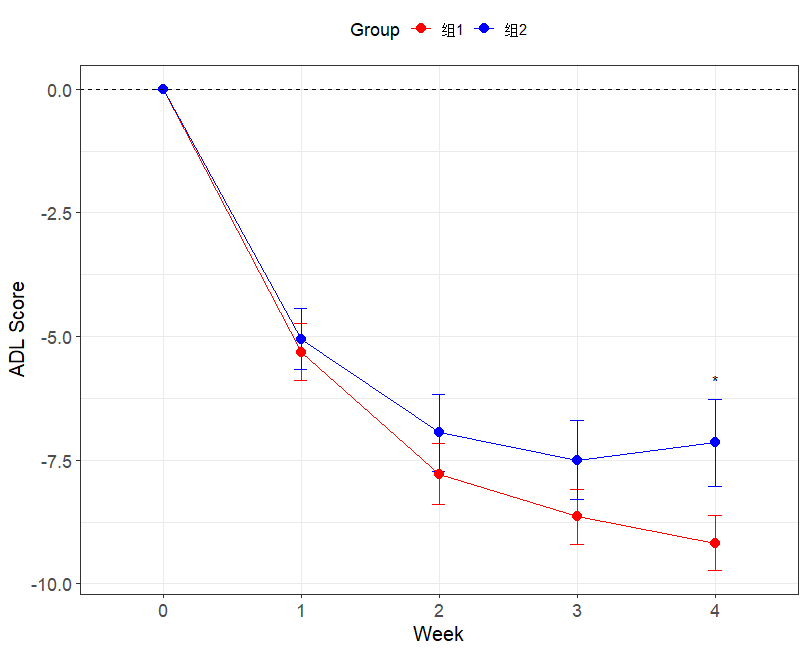
所用R包: tidyverse 1.所需数据计算 t1 <- tibble(id=rep(1:25,each=4),group=1,period=rep(c(1:4),25),value=rnorm(n = 100, mean = 2, sd = 1)) t2 <- tibble(id=rep(1:25,each=4),group=2,…