注:整理了日常工作中,对于数据变量添加标签的需求 所用R包:openxlsx, Hmisc, haven R语言添加标签(stata导出可用) # 简单添加 var_labels <- () #给出标签向量 data <- imap(data, ~ { label(data[[.y]]) <- var_labels…
注:此文章整理了常用的统计图绘图代码 所用r包:ggplot2 饼图 p <- ggplot(pdata2,aes(x = factor(1),percent,fill=type))+geom_col(colour = "white")+ coord_polar(theta = "y", start = 0) + geom_text(aes(…
注:在日常使用r语言保留数据的小数位数时,常会碰到小数位数强制取整的情况,如2.00会保存为2,本文介绍了我在遇到此问题时的处理方法 所用r包:tidyverse #将所有数值型变量的小数位数统一 format_column <- function(column) { if (is.numeric(column)) { # 识别每列的原始小数…
注:本章内容介绍了excel中常用的查询填补法,该方法相较于Excel中的功能更为强大,自定义程度高,可规定按照查询到的值替换原数据或仅替换原数据的缺失值。 数据集比较 #修改数据格式使对应 bcdata <- bcdata %>% mutate(across(all_of(variables),~as.numeric(as.chara…
所用r包:meta 待更新 单组连续型统计量 单组率 # 导入excel为列表 sheets <- getSheetNames("7d数据分析提取表.xlsx") data_frame <- lapply(sheets, read.xlsx, xlsxFile="7d数据分析提取表.xlsx") # assigning names to…
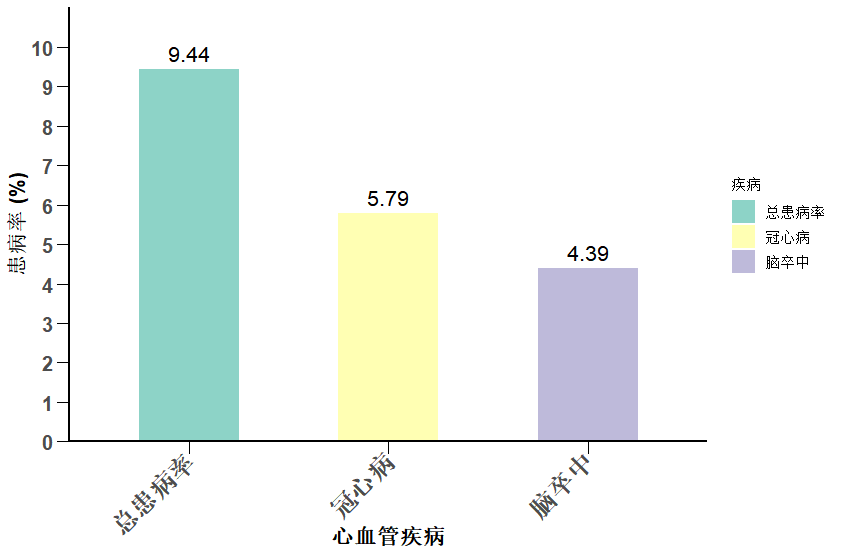
所用r包 library(tidyverse)library(openxlsx) 数据导入和预处理 adam <- read.csv("青春末期随访24.11.12录入完毕数据.csv") #空值转为缺失 adam <- adam %>% mutate(across(everything(),~ifelse(.=="",NA,.))) …
参考资料:周志华《机器学习》 待更新 在高维情形下出现的数据样本稀疏、距离计算困难等问题是所有机器学习方法共同面临的严重障碍,被称为“维数灾难”(curseofdimensionality)缓解维数灾难的一个重要途径是降维(dimensionreduction),亦称“维数约简”,即通过某种数学变换将原始高维属性空间转变为一个低维“子空间“,很多时…
特征选择 基础知识 对一个学习任务来说,给定属性集,其中有些属性可能很关键、很有用,另一些属性则可能没什么用.我们将属性称为“特征”(feature),对当前学习任务有用的属性称为“相关特征”(relevant feature)、没什么用的属性称为“无关特征”(irrelevant feature).从给定的特征集合中选择出相关特征子集的过程,称为…
参考资料:周志华著《机器学习》 基础知识 在“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础.此类学习任务中研究最多、应用最广的是“聚类”(clustering)。聚类既能作为一个单独过程,用于找寻数据内在的分布结构,也…
参考视频:10 EM算法(1):餐前小甜点——回顾MLE_哔哩哔哩_bilibili 极大似然估计与EM的联系 极大似然估计回顾 举例 极大似然法求解 有缺失情况计算十分复杂,引入em思维 EM算法举例 盒子中有两枚硬币a和b,从中摸一个硬币抛掷10次,记录正反次数,求硬币a和硬币b的正面概率 若知道摸出的硬币是a还是b 若不知道摸出的硬币是哪一个…