本文最后更新于 416 天前,其中的信息可能已经有所发展或是发生改变。
所用r包:meta
待更新
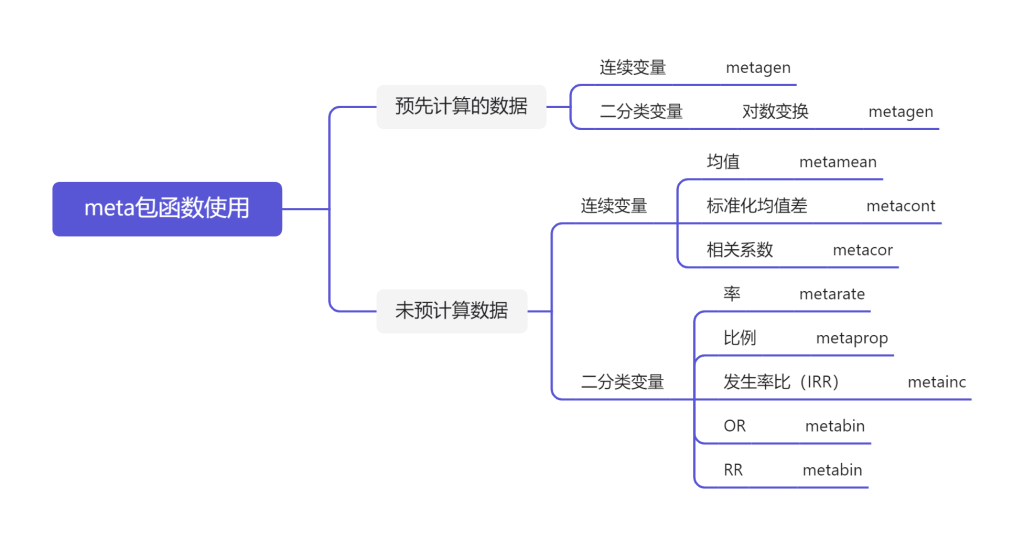
单组连续型统计量
单组率
# 导入excel为列表
sheets <- getSheetNames("7d数据分析提取表.xlsx")
data_frame <- lapply(sheets, read.xlsx, xlsxFile="7d数据分析提取表.xlsx")
# assigning names to data frame
names(data_frame) <- sheets
#选择效应量的合并方法
rate <- transform(data_frame[[4]],
p = x/n,
log=log(x/n),
logit=log((x/n)/(1-x/n)),
arcsin.size=asin(sqrt(x/(n+1))),
darcsin=0.5*(asin(sqrt(x/(n+1)))+asin((sqrt(x+1)/(n+1)))))
shapiro.test(exa1$p) # sm="PRAW" 没有转换的原始率
shapiro.test(exa1$log) # sm="PLN" 对数转换
shapiro.test(exa1$logit) # sm="PLOGIT" logit变换
shapiro.test(exa1$arcsin) # SM="PAS" 反正弦
shapiro.test(exa1$darcsin) # SM="PFT" 双重反正弦
metaresults1 <- list()
#批量求meta分析结果
for(sheet_name in names(data_frame)){
metaresults1[[sheet_name]] <- metaprop(x, n, studlab=paste(作者, year), data = data_frame[[sheet_name]], sm="PAS", incr = 0.5, allincr = FALSE, addinc = FALSE)
}
#在桌面创建对应的文件夹
desktop_path <- file.path(Sys.getenv("USERPROFILE"), "Desktop")
filename <- "7dmeta"
dir.create(paste0(desktop_path,"/",filename))
foldernames <- c("森林图_单组率","异质性图_单组率","漏斗图_单组率")
for (i in 1:3){
dir.create(paste0(desktop_path,"/",filename,"/",foldernames[i]))
}
#批量绘图并导出为jpg格式到对应文件夹
# 森林图
for (sheet_name in names(data_frame)) {
jpeg(paste0(desktop_path,"/",filename,"/",foldernames[1],"/",sheet_name, ".jpg"), width = 800, height = 600, units = "px", quality = 100)
forest(metaresults1[[sheet_name]], digits = 2)
dev.off()
}
# 异质性图
for (sheet_name in names(data_frame)) {
jpeg(paste0(desktop_path,"/",filename,"/",foldernames[2],"/",sheet_name, ".jpg"), width = 800, height = 600, units = "px", quality = 100)
radial(metaresults1[[sheet_name]], level = 0.95, text =data_frame[[sheet_name]]$zuozhe)
dev.off()
}
# 漏斗图
for (sheet_name in names(data_frame)) {
jpeg(paste0(desktop_path,"/",filename,"/",foldernames[3],"/",sheet_name, ".jpg"), width = 800, height = 600, units = "px", quality = 100)
funnel(metaresults1[[sheet_name]])
dev.off()
}
# 发表偏倚检验
metabias(meta1, method = "linreg", plotit = TRUE, k.min = 5) # Egger检验
metabias(meta1, method = "peters", plotit = TRUE, k.min = 5)
# Method 参数包括linreg代表egger检验;peters代表peter检验
# plotit 为画图函数;
# k.min 为进行检验时所需最小的单个研究的数量,默认为 10,如果研究在3~10个之间可通过此函数进行调整.
#批量化
egger_results <- lapply(metaresults2, function(x) {
metabias(x, method = "linreg", plotit = FALSE,k.min=1) # 不画图,减少计算量
})
# 显示Egger检验的结果
egger_results
#合并结果
egger_df <- do.call(rbind, lapply(egger_results, function(res) {
if (!is.null(res$p.value) && !is.null(res$statistic)) {
data.frame(
p_value = res$p.value,
test_statistic = res$statistic,
method = "Egger"
)
} else {
NULL
}
}))
write.xlsx(egger_df,"14天egger检验.xlsx")
#敏感性分析
metainf(meta1) # 行敏感性分析,计算分别剔除每个入选研究后合并的 OR 值及 95%可信区间。
#批量化
sensitivity_results <- lapply(metaresults2, function(x) {
metainf(x) # 逐一排除分析
})
# 显示逐一排除敏感性分析的结果
sensitivity_results
#导出结果
wb <- createWorkbook()
for (i in seq_along(sensitivity_results)){
addWorksheet(wb, sheetName = names(sensitivity_results)[i])
writeData(wb, sheet = names(sensitivity_results)[i], x = as_tibble(sensitivity_results[[i]]))}
saveWorkbook(wb, "14天敏感性分析表格.xlsx", overwrite = TRUE)
#剔除最大异质性点的敏感性分析结果
summary_sensitivity <- tibble()
for (i in seq_along(metaresults2)){
meta_obj <- metaresults2[[i]]
std_residuals <- (meta_obj$TE - meta_obj$TE.random) / sqrt(meta_obj$seTE^2 + meta_obj$tau^2)
high_residual_indices <- which.max(abs(std_residuals))
sensitivity_result <- as_tibble(sensitivity_results[[i]])[high_residual_indices,]
sensitivity_result$指标 <- names(metaresults2)[i]
summary_sensitivity <- bind_rows(summary_sensitivity,sensitivity_result)
}
write.xlsx(summary_sensitivity,"14天去除异质性最大文章结果.xlsx")