
参考资料:周志华《机器学习》
待更新
在高维情形下出现的数据样本稀疏、距离计算困难等问题是所有机器学习方法共同面临的严重障碍,被称为“维数灾难”(curseofdimensionality)
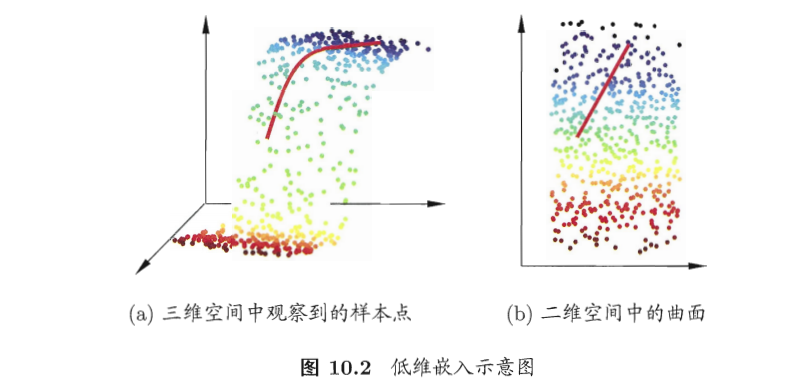
缓解维数灾难的一个重要途径是降维(dimensionreduction),亦称“维数约简”,即通过某种数学变换将原始高维属性空间转变为一个低维“子空间“,很多时候,人们观测或收集到的数据样本虽是高维的,但与学习任务密切相关的也许仅是某个低维分布,即高维空间中的一个低维“嵌入”。
多维缩放MDS




基于线性变换来进行降维的方法称为线性降维方法,它们都符合式(10.13)的基本形式,不同之处是对低维子空间的性质有不同的要求,相当于对 W施加了不同的约束.在下一节我们将会看到,若要求低维子空间对样本具有最大可分性,则将得到一种极为常用的线性降维方法.
主成分分析PCA
PCA基本思想
对于正交属性空间中的样本点,如何用一个超平面(直线的高维推广)对所有样本进行恰当的表达?容易想到,若存在这样的超平面,那么它大概应具有这样的性质:
最近重构性:样本点到这个超平面的距离都足够近
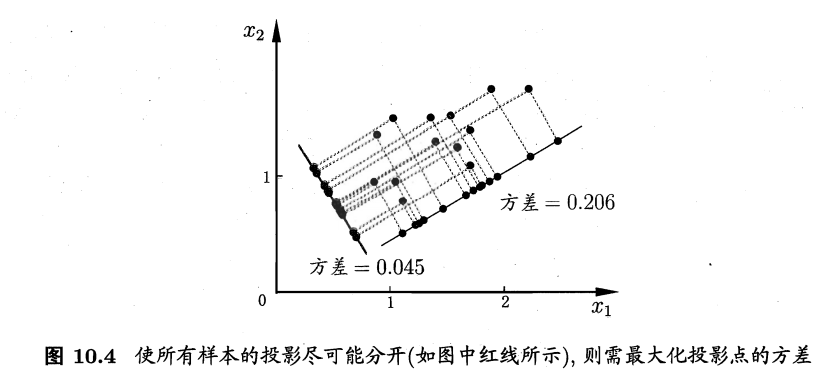
最大可分性:样本点在这个超平面上的投影能尽可能分开


根据最近重构性

根据最大可分性


核化线性降维
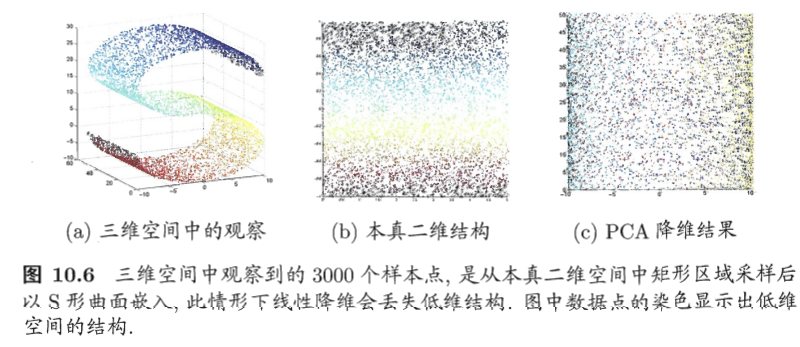
线性降维方法假设从高维空间到低维空间的函数映射是线性的,然而,企不少现实任务中,可能需要非线性映射才能找到恰当的低维嵌入,图10.6给出了一个例子,样本点从二维空间中的矩形区域采样后以S形曲面嵌入到三维空间,若直接使用线性降维方法对三维空间观察到的样本点进行降维,则将丢失原本的低维结构.为了对“原本采样的”低维空间与降维后的低维空间加以区别,我们称前者为“本真”(intrinsic)低维空间.
核主成分分析



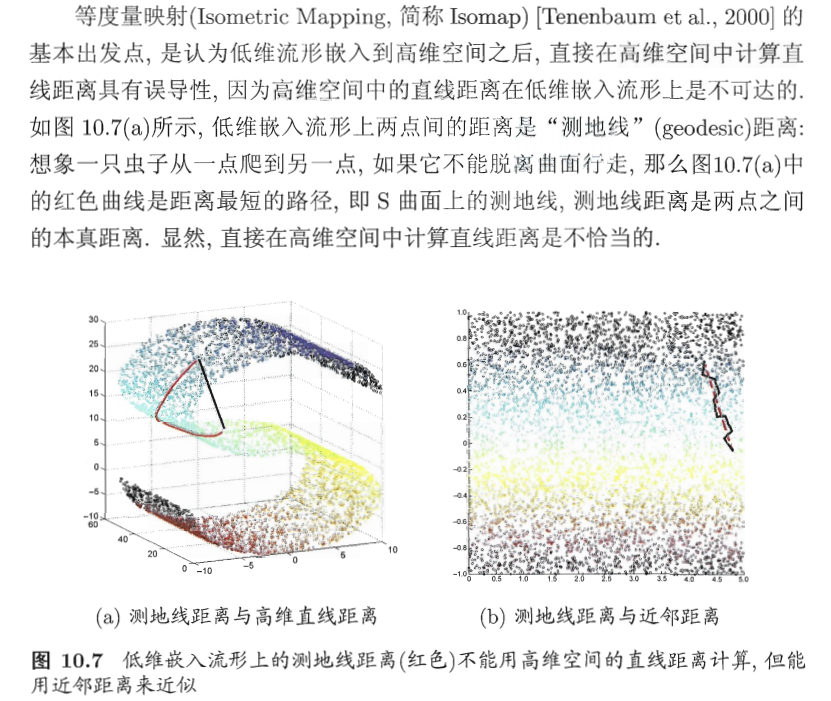
等度量映射

局部线性嵌入
与Isomap试图保持近邻样本之间的距离不同,局部线性嵌入(Locallyinear Embedding,简称LLE)|Roweis and Saul,2000]试图保持邻域内样本之间的线性关系.
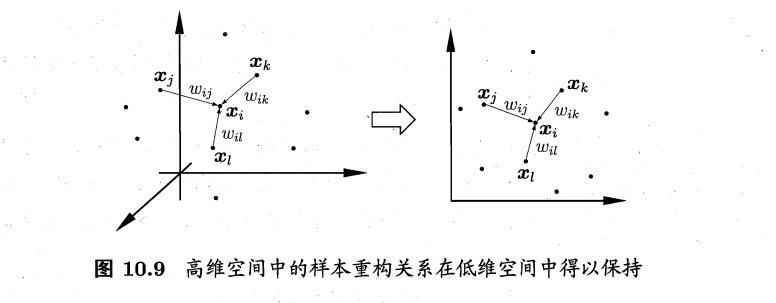
如图10.9所示,假定样本点xi的坐标能通过它的邻域样本xj;xk,xl的坐标通过线性组合而重构出来,即


度量学习
在机器学习中,对高维数据进行降维的主要目的是希望找到一个合适的低维空间,在此空间中进行学习能比原始空间性能更好.事实上,每个空间对应了在样本属性上定义的一个距离度量,而寻找合适的空间,实质上就是在寻找一个合适的距离度量.那么,为何不直接尝试“学习”出一个合适的距离度量呢?这就是度量学习(metric learning)的基本动机。







