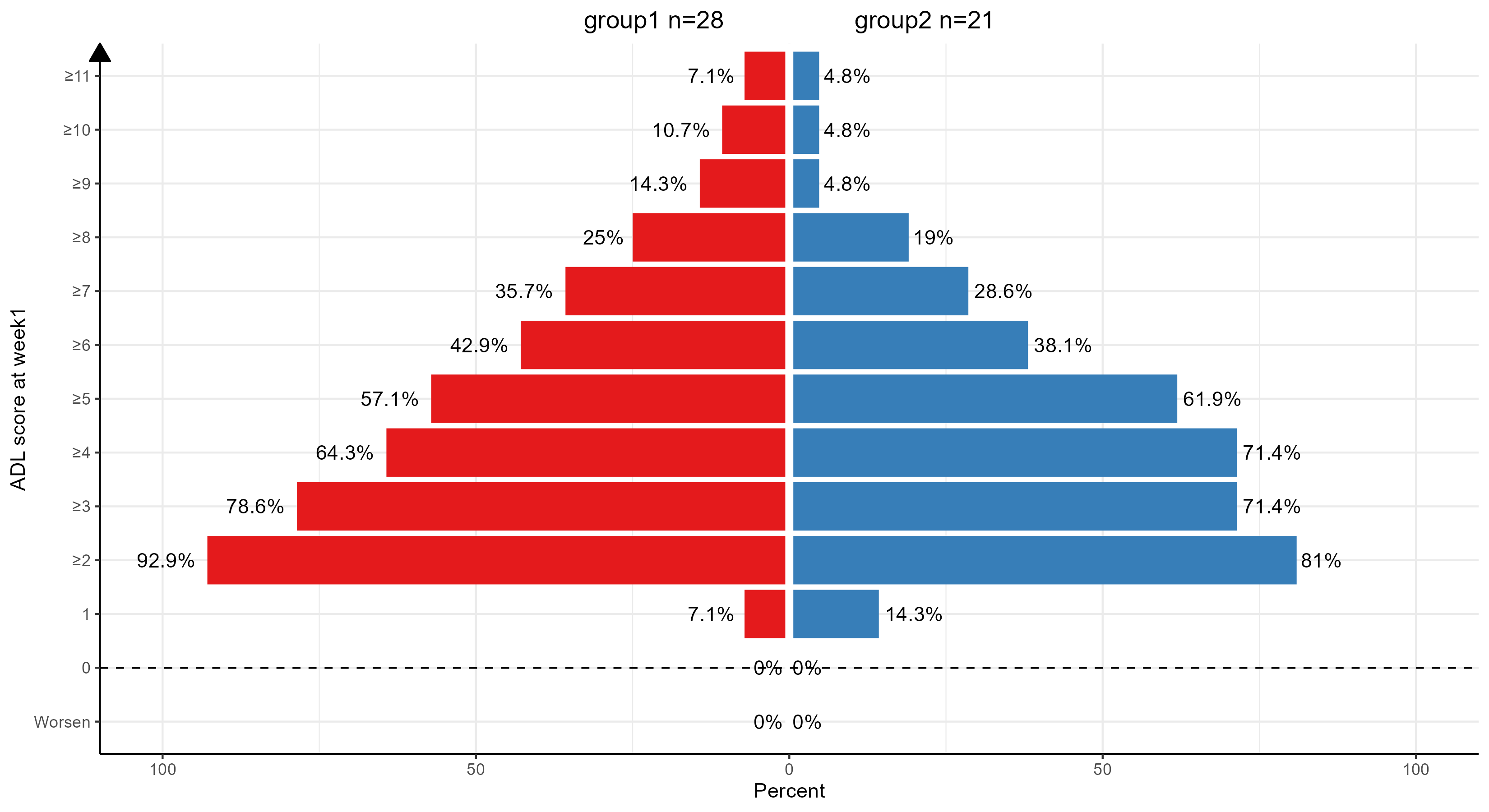
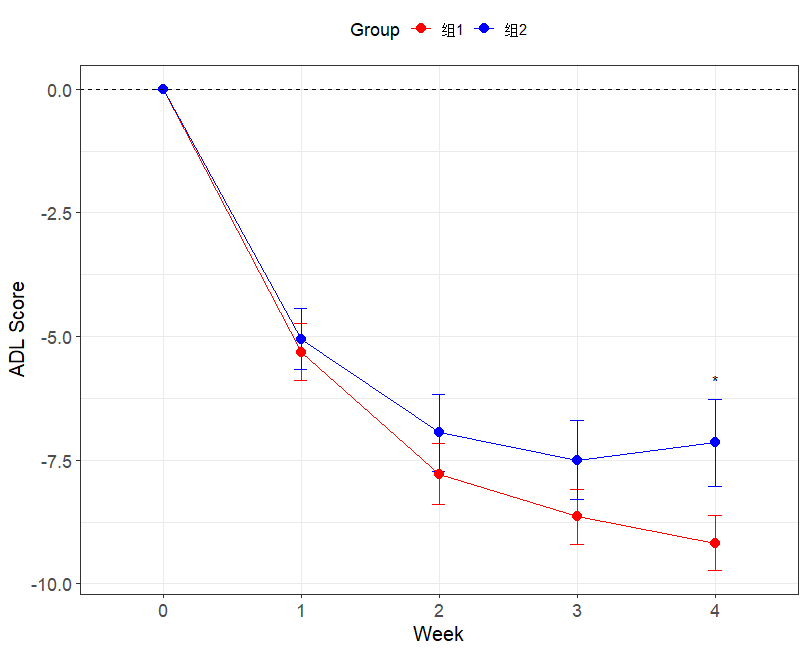
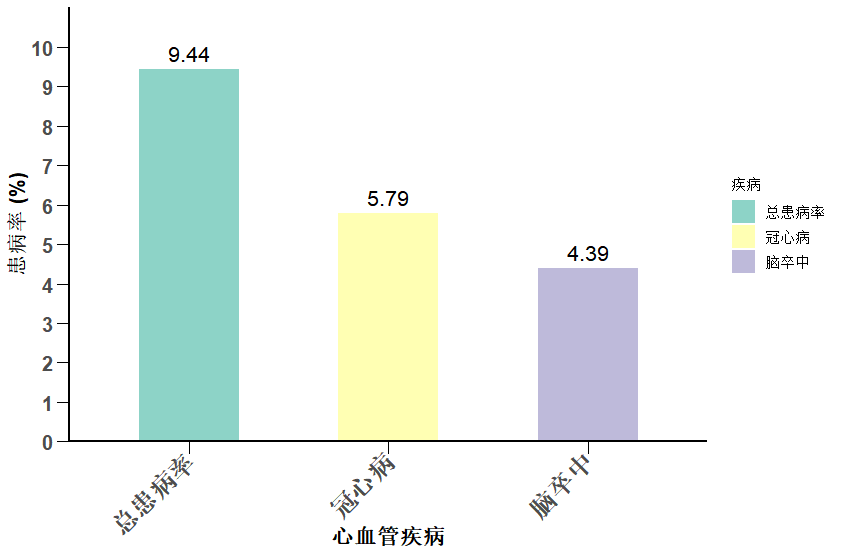
本文最后更新于 514 天前,其中的信息可能已经有所发展或是发生改变。
简介:批量两样本孟德尔随机化、中介孟德尔随机化及多变量孟德尔随机化代码
确认GWAS网站令牌
Sys.getenv("HOME") #查找根目录,更新api
ieugwasr::get_opengwas_jwt() #查看令牌
ieugwasr::api_status() #查看api状态抽取工具变量
# 设定暴露id
exposure_datc <- c('ieu-a-31')# 按需添加或减少更多的outcome
exposure_dats <- list()
for (i in seq_along(exposure_datc)) {
exposure_dat<-extract_instruments(outcomes=exposure_datc[i],
p1=5e-05, #设定选取的相关性p值,默认为-08
clump=TRUE, r2=0.001, #去掉连锁不平衡
kb=10000,access_token= NULL)
exposure_dats[[i]] <- exposure_dat}
# 筛除弱工具变量
#查看并剔除暴露1
get_f<-function(dat,F_value=10){
log<-is.na(dat$eaf.exposure)
log<-unique(log)
if(length(log)==1)
{if(log==TRUE){
print("数据不包含eaf,无法计算F统计量")
return(dat)}
}
if(is.null(dat$beta.exposure[1])==T || is.na(dat$beta.exposure[1])==T){print("数据不包含beta,无法计算F统计量")
return(dat)}
if(is.null(dat$se.exposure[1])==T || is.na(dat$se.exposure[1])==T){print("数据不包含se,无法计算F统计量")
return(dat)}
if(is.null(dat$samplesize.exposure[1])==T || is.na(dat$samplesize.exposure[1])==T){print("数据不包含samplesize(样本量),无法计算F统计量")
return(dat)}
if("FALSE"%in%log && is.null(dat$beta.exposure[1])==F && is.na(dat$beta.exposure[1])==F && is.null(dat$se.exposure[1])==F && is.na(dat$se.exposure[1])==F && is.null(dat$samplesize.exposure[1])==F && is.na(dat$samplesize.exposure[1])==F){
R2<-(2*(1-dat$eaf.exposure)*dat$eaf.exposure*(dat$beta.exposure^2))/((2*(1-dat$eaf.exposure)*dat$eaf.exposure*(dat$beta.exposure^2))+(2*(1-dat$eaf.exposure)*dat$eaf.exposure*(dat$se.exposure^2)*dat$samplesize.exposure))
F<- (dat$samplesize.exposure-2)*R2/(1-R2)
dat$R2<-R2
dat$F<-F
dat<-subset(dat,F>F_value)
delnumber <- nrow(subset(dat,F<=F_value))
print(paste("删除了",delnumber,"个弱工具变量"))
return(dat)
}
}
# 补充样本量(如缺失)
samplesize <- c(2505,2505,2505,2625,2625)
for (i in seq_along(exposure_datc)) {
exposure_dats[[i]]$samplesize.exposure <- samplesize[i]}
# 过滤弱工具变量
for ( i in seq_along(exposure_dats)){
exposure_dats[[i]] <- get_f(exposure_dats[[i]],F_value=10)
}
提取结果数据
# 设定结局id
outcome_dats <- c("finn-b-R18_ABNORMAL_SPERMATOZ","finn-b-N14_MALEINFERT")
result_dats <- list()
for (i in seq_along(exposure_dats)) {
current_results <- list()
for (n in seq_along(outcome_dats)){
# 提取当前 exposure_dat 的 SNP 列
exposure_dat <- exposure_dats[[i]]
snps <- exposure_dats[[i]]$SNP
outcome <- outcome_dats[n]
# 根据 SNP 列生成对应的 outcome_dat,并将其存储到 outcome_dats 列表中
result_dat<- extract_outcome_data(snps = snps,
outcome = outcome,
proxies = FALSE,
maf_threshold = 0.01,
access_token = NULL)
# 效应等位与效应量保持统一
if (is.null(result_dat)) {
next
}
adjresult_dat<- harmonise_data(exposure_dat = exposure_dat,
outcome_dat = result_dat)
current_results[[paste0("result_dat", i, "_", n)]] <- adjresult_dat
}
result_dats[[paste0("result_dat", i)]] <- current_results
}
MR分析
result_res <- list()
for (i in names(result_dats)){
current_results <- list()
for(n in names(result_dats[[i]])){
res <- mr(result_dats[[i]][[n]])
res[,"dataid"] <- i
res[,"samplesize.exposure"] <- result_dats[[i]][[n]][1,"samplesize.exposure"]
res[,"samplesize.outcome"] <- result_dats[[i]][[n]][1,"samplesize.outcome"]
res$lcl <- res$b - (1.96 * res$se)
res$ucl <- res$b + (1.96 * res$se)
res$or <- exp(res$b)
res$orlcl <- exp(res$lcl)
res$orucl <- exp(res$ucl)
current_results[[n]] <- res
}
result_res[[i]] <- current_results
}
# 合并列表的结果按照一个暴露数据一张表导出为excel
wb <- createWorkbook()
# 循环遍历 result_dats 中的每个数据框,并将其导出到工作簿的不同工作表中
for (i in names(result_res)) {
combined_data <- do.call(bind_rows, result_res[[i]])
# 将 combined_data 导出到工作簿的一个工作表中
addWorksheet(wb, sheetName = i)
writeData(wb, sheet = i, x = combined_data)
}
# 将工作簿保存为 Excel 文件
saveWorkbook(wb, "res结果.xlsx", overwrite = TRUE)异质性检验
# 4.1mr_presso来找出和处理离群值(也有检测异质性的功能)
for (i in names(result_dats)){
for(n in names(result_dats[[i]])){
if (nrow(result_dats[[i]][[n]]) < 3) {
next # 如果观测数小于2则无法进行presso分析跳过当前循环
}
t <- run_mr_presso(result_dats[[i]][[n]],NbDistribution = 1000)
indice <- t[[1]][["MR-PRESSO results"]][["Distortion Test"]][["Outliers Indices"]]
print(indice)
if (is.null(indice)) {
next # 如果未发现离群值则不输出
}
print(result_dats[[i]][[n]][indice,])
}}
# 删除上面输出提示的异常值
result_dats[["result_dat7"]][["result_dat7_2"]] <- result_dats[["result_dat7"]][["result_dat7_2"]][-indice,]
# 如发现异常SNP剔除异常值后再重新跑上面的mr分析
# 4.2异质性检验 mr_heterogeneity和水平多效性检验
result_heterogeneity <- list()
for (i in names(result_dats)){
current_results <- list()
for(n in names(result_dats[[i]])){
if (nrow(result_dats[[i]][[n]]) < 3) {
next # 如果观测数小于3则无法进行异质性检验分析跳过当前循环
}
a <- mr_heterogeneity(result_dats[[i]][[n]])# p<0.05表明存在异质性
b <- mr_pleiotropy_test(result_dats[[i]][[n]])
result <- bind_cols(a[1,],b[,c(5:7)])
current_results[[n]] <- result
}
result_heterogeneity[[i]] <- current_results
}
# 合并列表的结果按照一个暴露数据一张表导出为excel
wb <- createWorkbook()
# 循环遍历 result_dats 中的每个数据框,并将其导出到工作簿的不同工作表中
for (i in names(result_heterogeneity)) {
combined_data <- do.call(bind_rows, result_heterogeneity[[i]])
# 将 combined_data 导出到工作簿的一个工作表中
addWorksheet(wb, sheetName = i)
writeData(wb, sheet = i, x = combined_data)
}
# 将工作簿保存为 Excel 文件
saveWorkbook(wb, "暴露结局_heterogeneity.xlsx", overwrite = TRUE)绘图
# 创建存储文件夹
dir.create(file.path("figures"))
exposures <- c("暴露1") #这里根据实际暴露数量更改
chart_types <- c("散点图", "漏斗图", "留一森林图","森林图")
for (exposure in exposures) {
# 创建暴露目录
exposure_dir <- file.path("figures", exposure)
dir.create(exposure_dir)
# 对于每种图表类型,创建一个子目录
for (chart_type in chart_types) {
chart_dir <- file.path(exposure_dir, chart_type)
dir.create(chart_dir)
}
}
# 散点图
for (i in seq_along(result_dats)){
current_results <- list()
for(n in names(result_dats[[i]])){
file_name <- paste("figures/暴露", i,"/散点图/",n,".png", sep = "")
p1 <- mr_scatter_plot(result_res[[i]][[n]], result_dats[[i]][[n]])
ggsave(file_name, p1[[1]], width = 8, height = 6)
}
}
# 漏斗图
for (i in seq_along(result_dats)){
current_results <- list()
for(n in names(result_dats[[i]])){
file_name <- paste("figures/暴露", i,"/漏斗图/",n,".png", sep = "")
p2 <- mr_funnel_plot(singlesnp_results = mr_singlesnp(result_dats[[i]][[n]]))
ggsave(file_name, p2[[1]], width = 8, height = 6)
}
}
#5.3森林图
#5.3.1留一分析的森林图
for (i in seq_along(result_dats)){
current_results <- list()
for(n in names(result_dats[[i]])){
file_name <- paste("figures/暴露", i,"/留一森林图/",n,".png", sep = "")
res_loo <- mr_leaveoneout(result_dats[[i]][[n]])
p3 <- mr_leaveoneout_plot(res_loo)
ggsave(file_name, p3[[1]], width = 8, height = 6)
}
}
# 森林图
for (i in seq_along(result_dats)){
current_results <- list()
for(n in names(result_dats[[i]])){
file_name <- paste("figures/暴露", i,"/森林图/",n,".png", sep = "")
res_single <- mr_singlesnp(result_dats[[i]][[n]])
p4 <- mr_forest_plot(res_single)
ggsave(file_name, p4[[1]], width = 8, height = 6)
}
}
# 森林图美化版
bc <- read.xlsx("肠炎肠菌生殖孟德尔随机化/森林图.xlsx",1)
## 处理数据为数值型并调整小数位数
bc$se<-round(as.numeric(bc$se),8)
bc$or<-round(as.numeric(bc$or),3)
bc$orlcl<-round(as.numeric(bc$orlcl),3)
bc$orucl<-round(as.numeric(bc$orucl),3)
bc$pval<-round(as.numeric(bc$pval),3)
# 调整outcome列的缩进
bc$outcome<- ifelse(!is.na(bc$samplesize.outcome), bc$outcome, paste0(" ", bc$outcome))
########把缺失值设置为空白以避免图形中显示为NA不美观
bc$samplesize.outcome<- ifelse(is.na(bc$samplesize.outcome), "", bc$samplesize.outcome)
bc$pval <- ifelse(is.na(bc$pval), "", bc$pval)
bc$outcome <- ifelse(is.na(bc$outcome), "", bc$outcome)
########创建一个空白列用于放图形
bc$` ` <- paste(rep(" ", 20), collapse = " ")
########创建新列名OR (95% CI)
bc$`OR (95% CI)` <- ifelse(is.na(bc$se), "",
sprintf("%.3f (%.3f - %.3f)",
bc$or, bc$orlcl, bc$orucl))#sprintF返回字符和可变量组合
tm <- forest_theme(base_size = 10, #文本的大小
# Confidence interval point shape, line type/color/width
ci_pch = 15, #可信区间点的形状
ci_col = "#762a83", #CI的颜色
ci_fill = "#0000FF80", #ci颜色填充
ci_alpha = 0.8, #ci透明度
ci_lty = 1, #CI的线型
ci_lwd = 2, #CI的线宽
ci_Theight = 0.2, # Set an T end at the end of CI ci的高度,默认是NULL
# Reference line width/type/color 参考线默认的参数,中间的竖的虚线
refline_lwd = 1, #中间的竖的虚线
refline_lty = "dashed",
refline_col = "grey20",
# Vertical line width/type/color 垂直线宽/类型/颜色 可以添加一条额外的垂直线,如果没有就不显示
vertline_lwd = 1, #可以添加一条额外的垂直线,如果没有就不显示
vertline_lty = "dashed",
vertline_col = "grey20",
# Change summary color for filling and borders 更改填充和边框的摘要颜色
summary_fill = "yellow", #汇总部分大菱形的颜色
summary_col = "#4575b4",
# Footnote font size/face/color 脚注字体大小/字体/颜色
footnote_cex = 0.6,
footnote_fontface = "italic",
footnote_col = "red")
forestplot <- forest(bc[,c(1,2,10,11,6)], #这里分别对应图形1-5列的显示数值,第三列为空白用来画图
est = bc$or, #效应值
lower = bc$orlcl, #可信区间下限
upper = bc$orucl, #可信区间上限
# sizes = bc$se, #(感觉这里可加可不加,如加则取消注释)
ci_column = 3.2, #在那一列画森林图,要选空的那一列
ref_line = 1,
arrow_lab = c(" ", " "),
xlim = c(0, 2), #森林图轴的范围
ticks_at = c(0, 0.5, 1, 1.5, 2), #森林图刻度
footnote = "OR, odds ratio; IVX, inverse variance weighting; CI, confidence interval.",
theme = tm)
ggsave("森林图.png",forestplot, width = 8, height = 6)