本文最后更新于 530 天前,其中的信息可能已经有所发展或是发生改变。
简介:无论进行何种统计分析,数据探索是分析数据前必做的准备工作。可帮助我们确认和发现数据的变量类型,数据中的缺失值、异常值,以此判断数据适合的分析方法及进行对应的数据处理。
所用R包:tidyverse、skimr、DataExplorer、GGally
#使用r自带数据集并设定变量类型
library(survival)
adam <- lung
adam$sex <- as.factor(adam$sex)
adam$status <- as.factor(adam$status)
查看数据的分布
#使用skimr包查看数据特点
skim(adam)
#使用GGally包可视化查看不同分类下的变量分布
p <- ggbivariate(adam, "status", c(1,2,4)) + scale_fill_brewer(type = "qual")
print(p)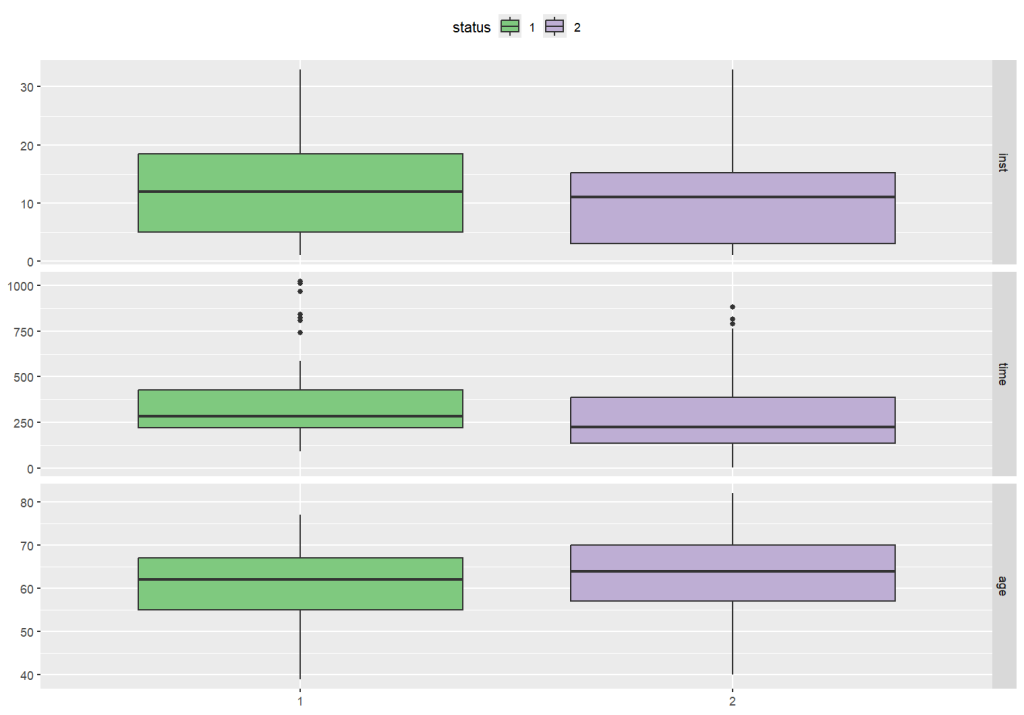
查看缺失值
#传统代码
any(is.na(adam$inst)) #查看指定变量有无缺失
sum(is.na(adam$inst)) #统计指定变量缺失个数
missing_summary <- sapply(adam, function(x) sum(is.na(x))) #查看数据集所有变量缺失情况
#使用skimr或者DataExplorer包统计缺失值并可视化缺失值的分布
a <- skim(adam)
a[a$n_missing>0,]$skim_variable #查看有缺失的变量名
a %>% filter(n_missing!=0)
#使用DataExplorer包可视化缺失值分布
profile_missing(adam)
plot_missing(adam)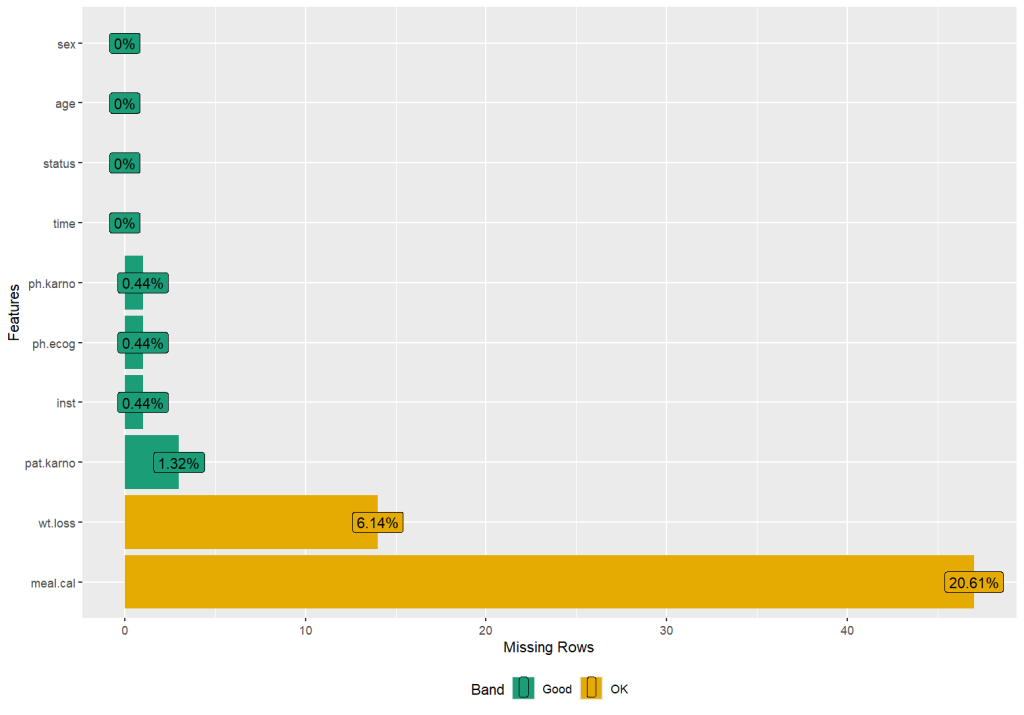
连续型变量异常值判断
#自定义函数
outliers1 = function(x, method = "boxplot", k= NULL,coef = NULL, lp = NULL, up = NULL){
if (class(x)!="numeric"){list(outliers = "提供的变量不是数值型")} else{
switch(method,
"sd"={
if(is.null(k)) k=3
mu = mean (x, na.rm = TRUE)
sd = sd(x, na.rm = TRUE)
LL = mu - k*sd
UL = mu + k*sd},
"boxplot" = {
if(is.null(coef)) coef = 1.5
Q1 = quantile(x, 0.25, na.rm = TRUE)
Q3 = quantile(x, 0.75, na.rm = TRUE)
iqr = Q3-Q1
LL = Q1 - coef*iqr
UL = Q3 + coef*iqr},
"percentiles"={
if(is.null(lp))lp = 0.025
if(is.null(up))up = 0.975
LL = quantile(x,lp, na.rm = TRUE)
UL = quantile(x,up, na.rm = TRUE)})
idx = which(x < LL | x > UL)
n = length(idx)
list(outliers = x [idx],outlier_idx = idx, outlier_num = n)
}}
#尝试不同方法
methods <- c("sd", "boxplot", "percentiles") # 用数据集某个变量比较三种方法并选择最好的方法
outliers <- sapply(methods, function(m) outliers1(adam$time, method = m)$outliers)
outlier_idx <- sapply(methods, function(m) outliers1(adam$time, method = m)$outlier_idx)
outlier_counts <- sapply(methods, function(m) outliers1(adam$time, method = m)$outlier_num)
best_method <- methods[which.min(outlier_counts)]
cat("Best method:", best_method, "\n") # 输出最好的方法和异常值数量
cat("Outlier count:", min(outlier_counts), "\n")
a <- sapply(adam,function(x) outliers1(x,method="sd")) #根据需求更改方法查看异常值数量
#异常值替换为缺失
adam1 <- adam %>% mutate(across(where(is.numeric),~if_else(. %in% outliers1(.)$outliers,NA,.))) #将异常值改为缺失
skim(adam)
skim(adam1) 查看更改后数据情况