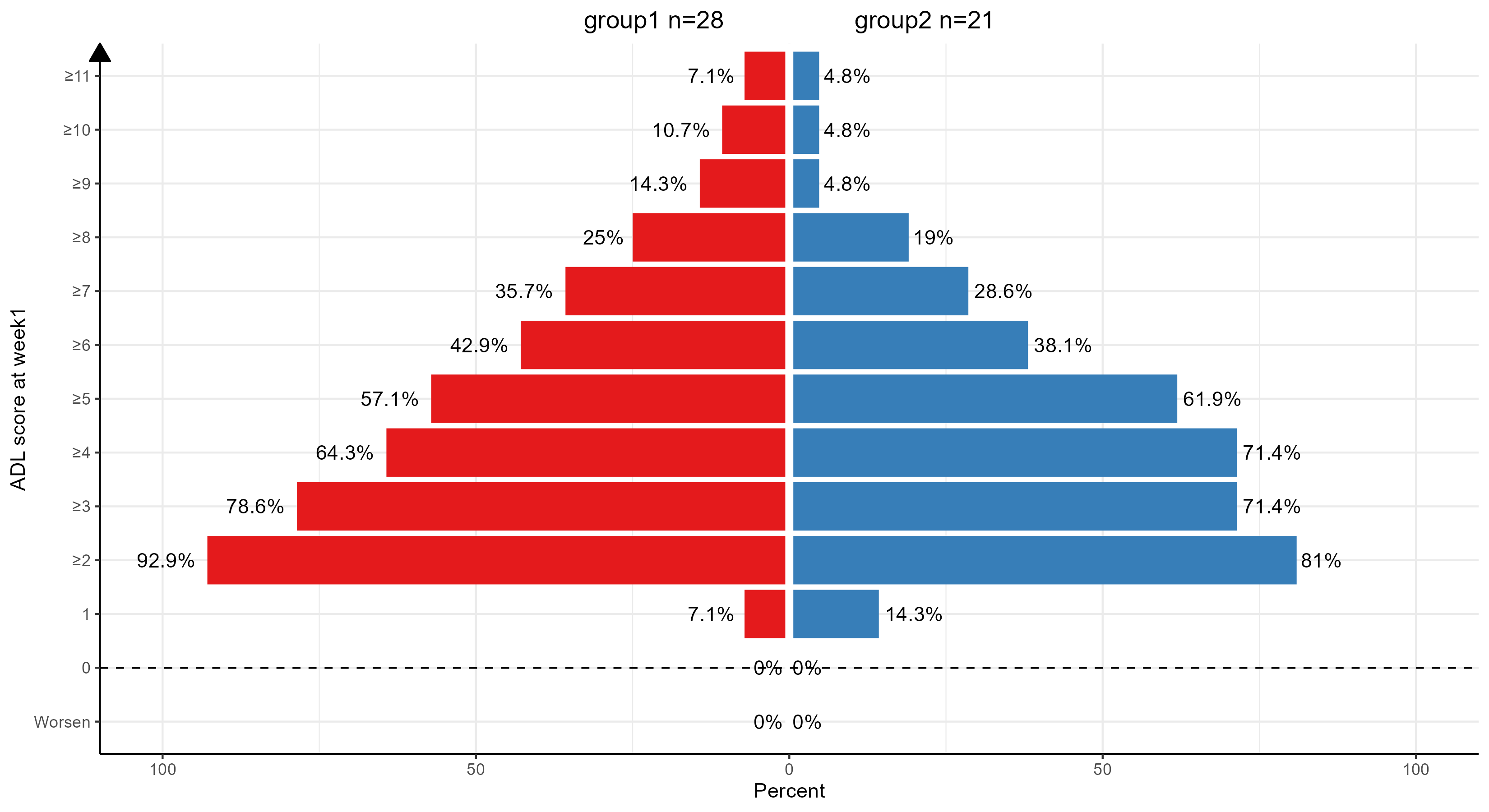
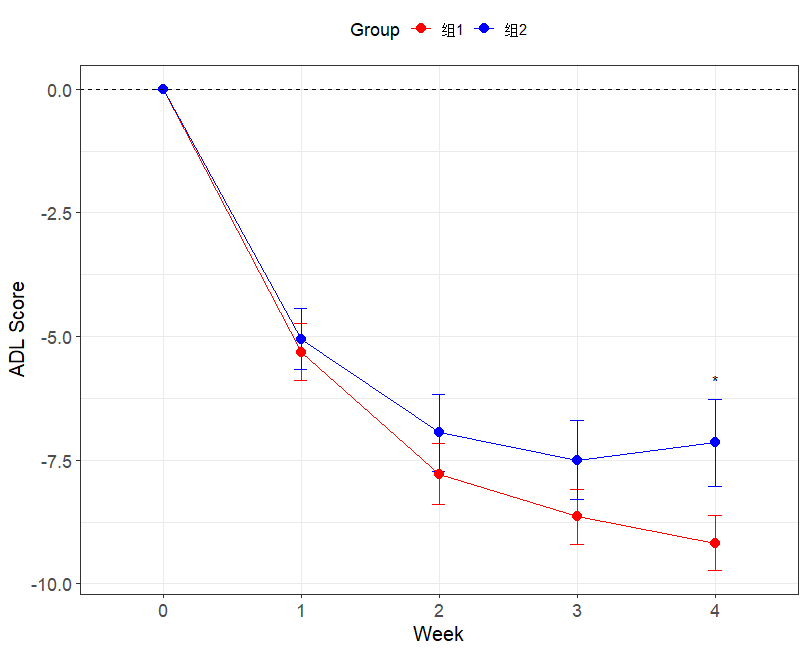
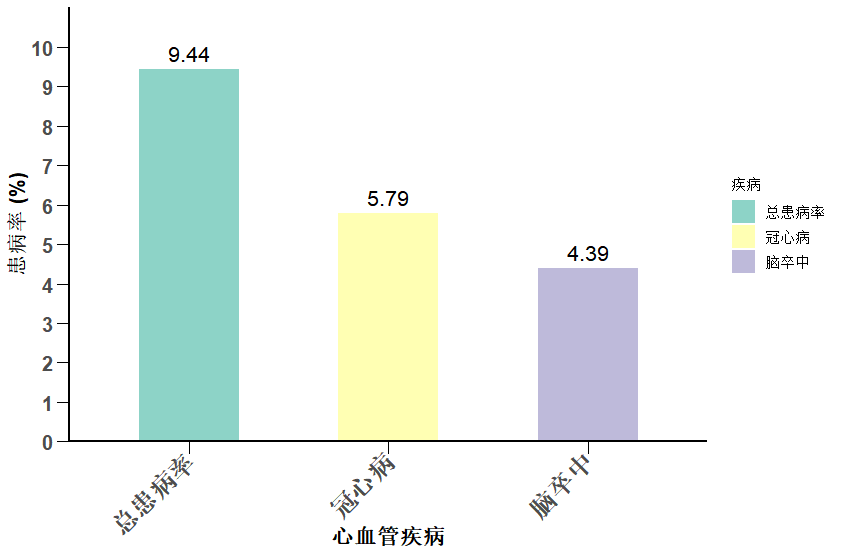
本文最后更新于 333 天前,其中的信息可能已经有所发展或是发生改变。
简介:解决读入外部数据时,由于编码格式问题导致的字符乱码及数据分析报错情况。
所用R包:stringi
变量名格式调整
names(data) <- iconv(names(data), to = "ASCII//TRANSLIT")
names(data) <- gsub("\\.", "_", names(data))
names(data) <- make.names(names(data)) export(data, "处理后数据.dta")数据编码调整
#查找变量
character_columns <- names(data)[sapply(data, function(x) inherits(x, "character"))]
#or data %>% select(where(~!is.character(.)))
labelled_columns <- names(data_cleaned)[sapply(data_cleaned, function(x) inherits(x, "haven_labelled"))]
date_columns <- names(data_cleaned)[sapply(data_cleaned, function(x) inherits(x, c("Date", "POSIXct")))]
# 检查是否所有字符列都被转换为 UTF-8 编码
for (col in colnames(adam1)) {
if (is.character(adam1[[col]])) {
if (!all(stri_enc_isutf8(adam1[[col]]))) {
stop(paste("Column", col, "contains non-UTF-8 encoded data."))
}
}
}
#查找非UTF-8 编码列
non_code <- data %>% select(where(~!all(stri_enc_isutf8(.))&& is.character(.))) %>% colnames()
# 尝试寻找变量的编码格式并转换字符列为 UTF-8 编码
possible_encodings <- c("GB2312", "GBK", "BIG5")
for (encoding in possible_encodings) {
print(paste("Trying encoding:", encoding))
try({
adam1$ar01 <- stri_encode(adam1$ar01, encoding, "UTF-8")
if (all(stri_enc_isutf8(adam1$ar01))) {
print(paste("Successfully converted using encoding:", encoding))
break
}
}, silent = TRUE)
}
#确定乱码的变量格式后将所有字符串转换为UTF-8 编码
data <- data %>% mutate(across(non_code,~ stri_encode(.,"GB2312", "UTF-8")))
# 检查是否所有字符列都被转换为 UTF-8 编码
for (col in colnames(adam1)) {
if (is.character(adam1[[col]])) {
if (!all(stri_enc_isutf8(adam1[[col]]))) {
stop(paste("Column", col, "contains non-UTF-8 encoded data."))
}
}
}