注:文章内容主要来自吴恩达老师的机器学习课程和周志华老师的《机器学习》
欠拟合和过拟合
仅使用简单线性回归会导致欠拟合,引入多项式回归当阶数逐渐过大时会导致过拟合
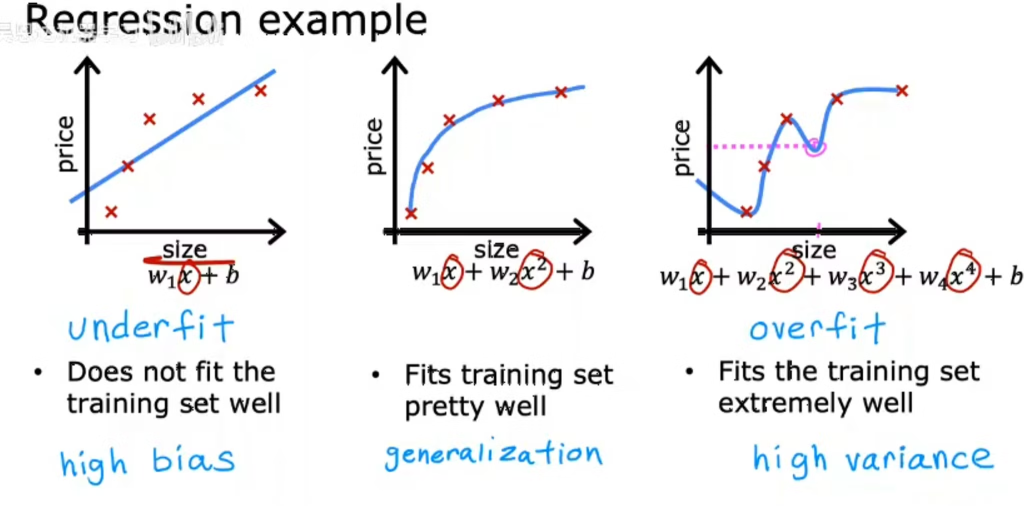
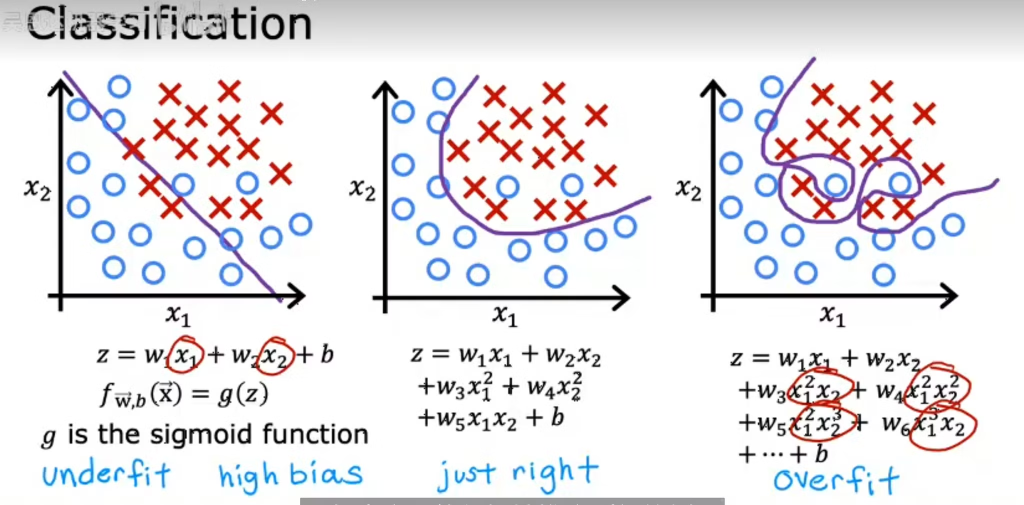
欠拟合导致偏差、方差均增高
过拟合情况下偏差较低,但方差增高
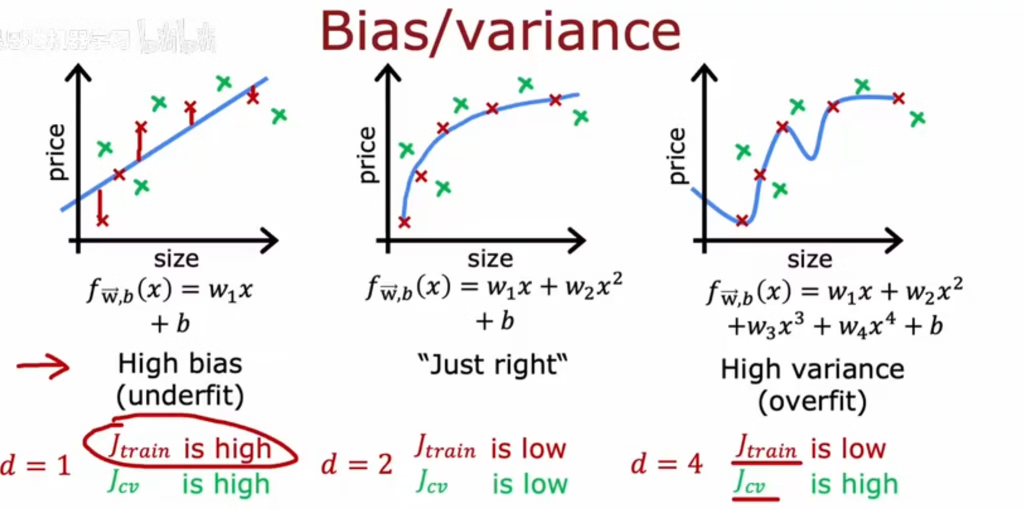
随模型阶数增加,偏差(训练集误差)逐渐降低,方差(测试集误差)先降低达到最低点后逐渐升高

过拟合解决方法
增加样本量;选择合适的特征;减小参数的数值大小(如引入正则化)
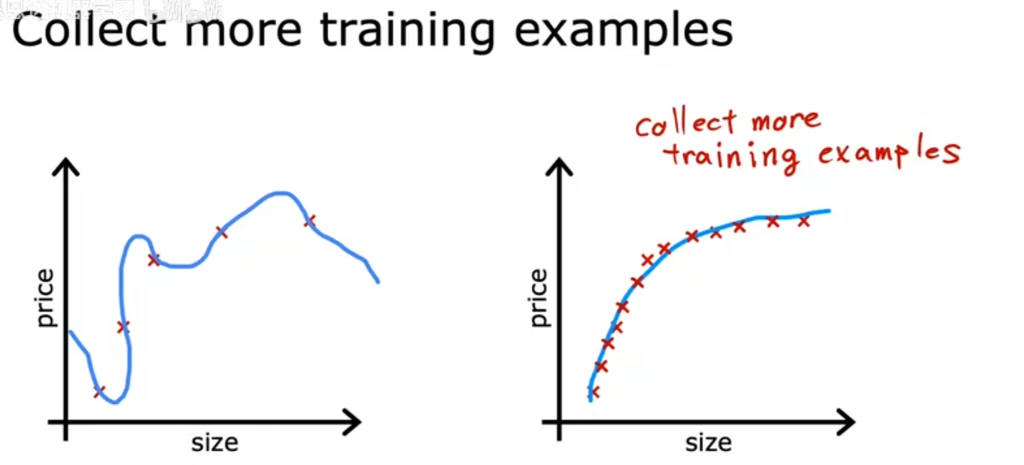
1.增加样本量
随样本量增大,方差降低
2.特征选择
样本量不足时,降低特征数量可降低过拟合程度
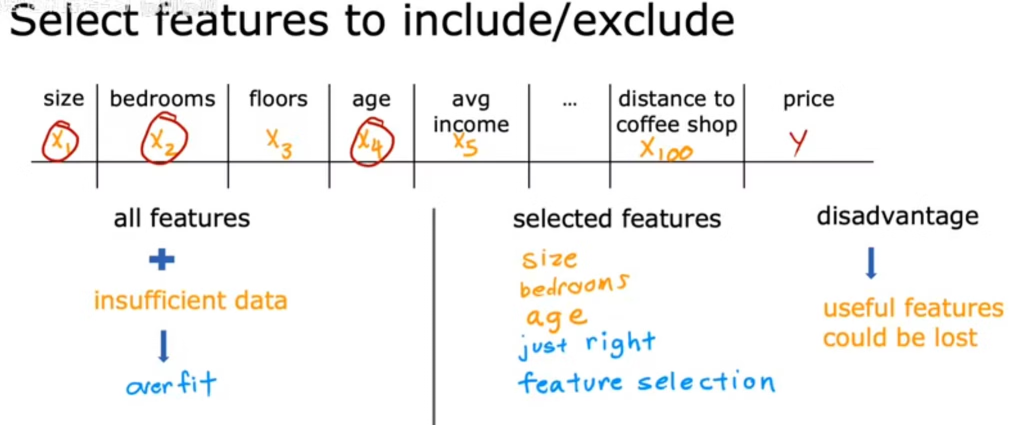
特征选择方法可参考文章:机器学习系列(10)-特征选择与稀疏表示
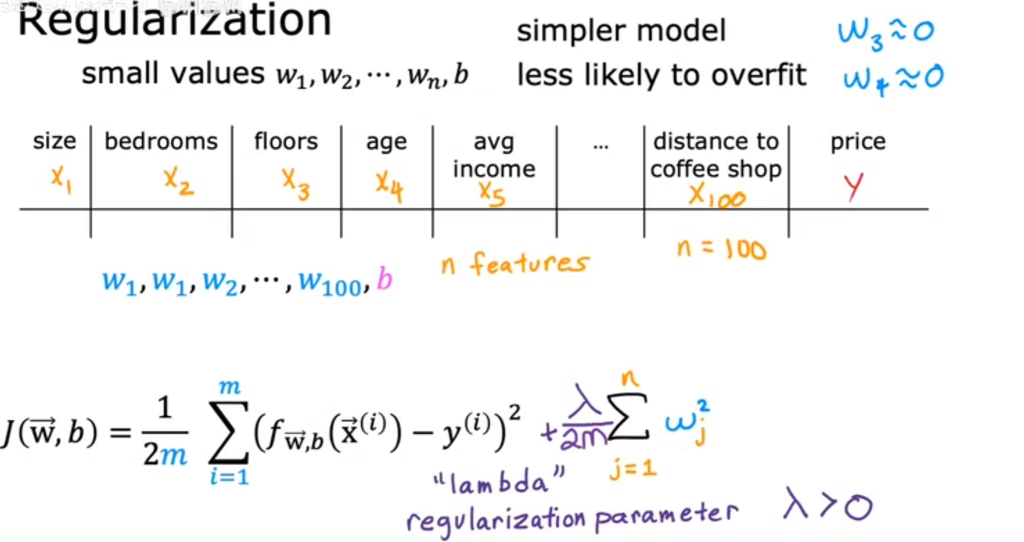
3.正则化
系数的数值降低,可发现曲线弯曲程度降低
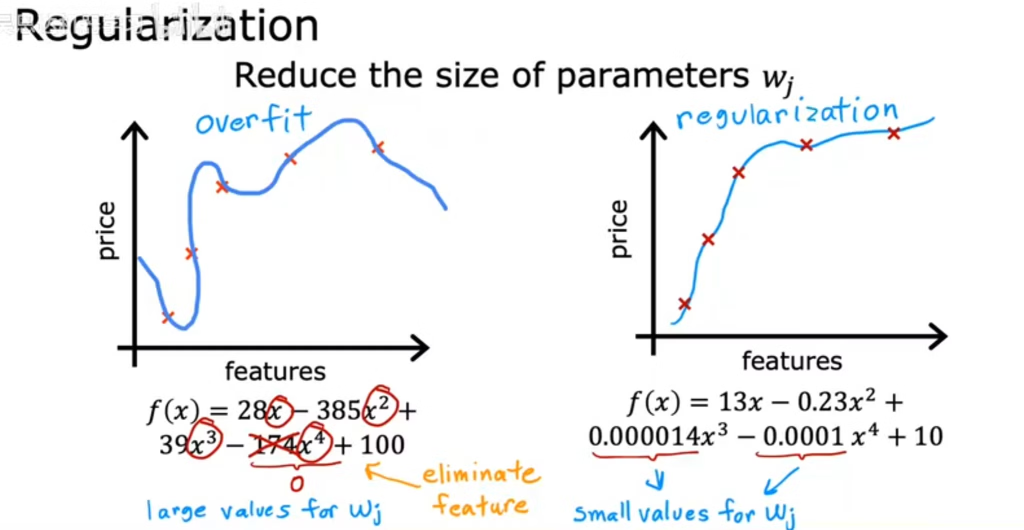
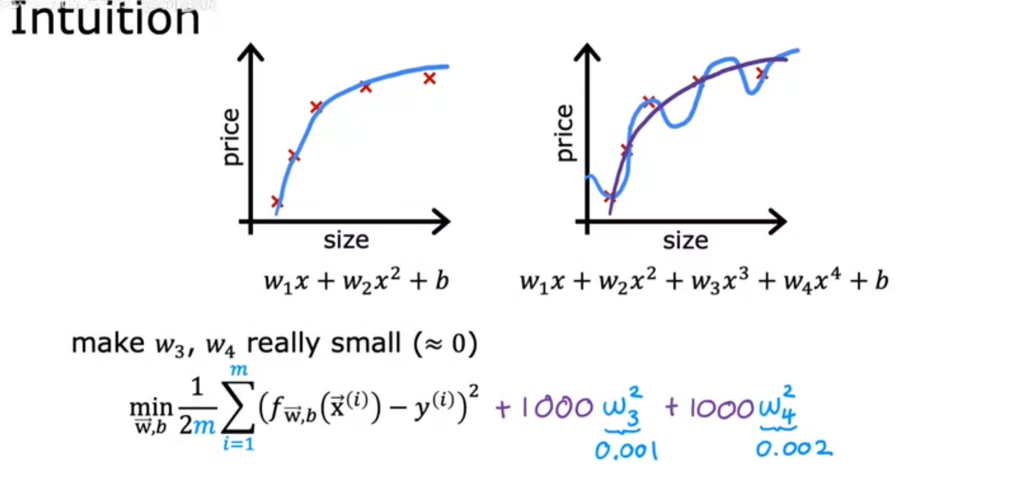
如何在控制偏差的情况下,尽量减少模型参数的大小,从而减小方差?
方法:在误差函数中加入正则化项+
L2正则化:岭回归,仅起到降低过拟合的效果
L1正则化:lasso回归,可将不重要的特征的系数降低为0,从而同时起到特征筛选的效果

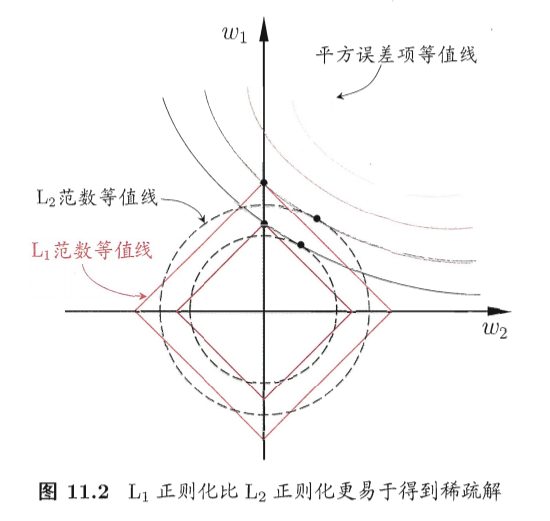
L1正则和L2正则的差别

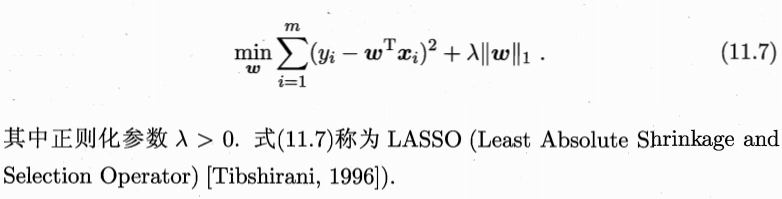
L1范数和L2范数正则化都有助于降低过拟合风险,但前者还会带来一个额外的好处:它比后者更易于获得“稀疏”(sparse)解,即它求得的w会有更少的非零分量。
为了理解这一点,我们来看一个直观的例子:假定仅有两个属性,于是无论式(11.6)还是(11.7)解出的 w 都只有两个分量,即 w1,w2,我们将其作为两个坐标轴,然后在图中绘制出式(11.6)与(11.7)的第一项的“等值线”,即在(qu1,w2)空间中平方误差项取值相同的点的连线,再分别绘制出1范数与2范数的等值线,即在(u1,o2)空间中1范数取值相同的点的连线,以及2范数取值相同的点的连线,如图11.2所示.式(11.6)与(11.7)的解要在平方误差项与正则化项之间折中,即出现在图中平方误差项等值线与正则化项等值线相交处,由图11.2可看出,采用L1范数时平方误差项等值线与正则化项等值线的交点常出现在坐标轴上,即w1或w2为0,而在采用L2范数时,两者的交点常出现在某个象限中,即w1或 w2均非0;换言之,采用L1正则比L2正则更易于得到稀疏解,
注意到w取得稀疏解意味着初始的d个特征中仅有对应着u的非零分量的特征才会出现在最终模型中,于是,求解L1范数正则化的结果是得到了仅采用一部分初始特征的模型;换言之,基于工正则化的学习方法就是一种嵌入式特征选择方法,其特征选择过程与学习器训练过程融为一体,同时完成。